Homelab - PART 2
sous le capot de mon homelab

Dans le ventre de Pisely
Dans le premier article, je posais les fondations de mon homelab: pourquoi je voulais un petit bout d’infrastructure à moi, pourquoi j’ai choisi Proxmox, et comment l’idée de Pisely est née quelque part entre une envie de bidouiller et une obsession pour le learning by doing. Cette fois-ci, on va ouvrir le capot.
L’objectif de cet article est simple: raconter ce qui tourne aujourd’hui sur Pisely, comment les briques se parlent, et ce que j’ai appris en passant d’un hyperviseur Proxmox à une petite plateforme applicative maison.
Le plan de bataille
Avant de parler de Gitea, Grafana, il faut comprendre le découpage global.
J’ai aujourd’hui trois grandes couches:
- Une couche infrastructure, portée par Proxmox, Terraform, Cloud-init et Ansible.
- Une couche Orchestrateur, basée sur K3s, qui héberge les services applicatifs.
- Une couche exposition, observabilité et applicatif, avec ingress-nginx, ExternalDNS, cert-manager, Cloudflare Tunnel, Prometheus et Grafana, Gitea et n8n.
Dit comme ça, ça sonne très sérieux. En réalité, le principe est assez simple: je veux pouvoir déclarer une machine, configurer les services de base, déployer des applications, leur donner un nom DNS, un certificat TLS, puis observer ce qui se passe.
Voici la vue mentale de l’ensemble:
Ce que Kubernetes ne fait pas chez moi
Une fois qu’on a un cluster Kubernetes, on peut vite tomber dans un réflexe un peu dangereux: vouloir tout mettre dedans.
Dans mon cas, j’ai choisi de garder certaines briques hors cluster, notamment PostgreSQL et BIND9.
PostgreSQL: sert de base relationnelle pour plusieurs services. Grafana, Gitea ou n8n n’ont pas besoin de chacun embarquer leur petite base jetable dans un chart Helm. Je préfère avoir une VM dédiée, configurée et sauvegardable à part. Ce n’est pas forcément le choix ultime pour tout le monde, mais pour mon homelab, c’est un bon compromis entre simplicité et contrôle.
BIND9, lui, joue le rôle de DNS local. Sans DNS propre, tout finit en IPs copiées-collées, en /etc/hosts, ou en noms de services qu’on ne comprend plus.
Ces deux briques sont configurées avec Ansible. Le playbook principal cible d’un côté les serveurs DNS, de l’autre les serveurs de base de données. Ansible est particulièrement adapté à ce rôle: décrire des états de configuration sur des machines existantes, avec des playbooks YAML, des rôles, des variables et des handlers.
K3s: Kubernetes, mais à taille humaine
K3s a un positionnement assez parfait pour ce genre de projet: c’est une distribution Kubernetes légère, pensée pour l’edge, l’IoT, le développement, et explicitement les homelabs. En clair, ça permet d’apprendre Kubernetes sans commencer par monter une usine à gaz.
Mon cluster sert aujourd’hui à héberger les services que je veux manipuler comme de vrais workloads applicatifs:
- Gitea pour le dépôt Git et les actions.
- n8n pour l’automatisation et le nocode.
- Prometheus pour collecter les métriques.
- Grafana pour visualiser et explorer ce qui se passe.
- ingress-nginx, cert-manager, ExternalDNS et Cloudflare Tunnel pour exposer tout ça proprement.
- Argo CD comme prochaine étape vers une logique GitOps plus assumée.
Ce qui est intéressant, ce n’est pas seulement la liste des outils. C’est le fait qu’ils forment une petite plateforme cohérente.
Un service n’est plus juste “un pod qui tourne”. Il a besoin d’un nom DNS, d’un certificat, d’un stockage persistant, parfois d’une base PostgreSQL externe, parfois d’un port TCP spécifique, et idéalement de métriques. C’est là que Kubernetes devient vraiment formateur: il force à penser aux interactions entre les briques.
Le point d’entrée: ingress-nginx
Dans mon cluster, ingress-nginx joue le rôle de porte d’entrée.
Pour le HTTP et le HTTPS, c’est le cas d’usage classique: un domaine arrive sur l’ingress, l’ingress route vers le bon service Kubernetes, et le navigateur finit par afficher quelque chose. Jusque-là, rien de très exotique. Mais Gitea amène un cas plus intéressant: le SSH.
Git sans SSH, c’est un peu triste. Dans ma configuration, Gitea expose son SSH sur 2222, et ingress-nginx est configuré pour router ce flux TCP vers le service interne Gitea. C’est un bon exemple de petit détail qui fait comprendre la différence entre “Ingress Kubernetes” au sens strict et “ingress-nginx” comme contrôleur capable d’aller un peu plus loin.
La documentation ingress-nginx explique justement que Kubernetes Ingress gère officiellement le trafic HTTP(S), mais que le contrôleur peut aussi exposer des services TCP/UDP via --tcp-services-configmap ingress-nginx TCP/UDP services.
Dans mon cas, ça me permet d’avoir une entrée cohérente pour le web et pour le SSH de Gitea, sans bricoler un chemin complètement séparé pour ce protocole.
DNS et certificats: le moment où l’infra devient agréable
Il y a un moment assez satisfaisant dans ce projet: quand le DNS et les certificats commencent à s’automatiser. Avant, exposer un nouveau service ressemblait souvent à une checklist manuelle:
- créer le service Kubernetes;
- ajouter un ingress;
- créer ou modifier une entrée DNS;
- demander un certificat;
- vérifier que tout pointe au bon endroit;
- recommencer parce qu’on a oublié un détail.
Aujourd’hui, l’idée est de réduire cette friction.
ExternalDNS observe les Ingress Kubernetes et pousse les entrées DNS dans ma zone via RFC2136 vers BIND9. Le provider RFC2136 d’ExternalDNS est documenté pour mettre à jour une zone DNS avec TSIG ExternalDNS RFC2136. Dans mon homelab, ça crée un lien direct entre ce qui est déclaré dans Kubernetes et ce qui existe côté DNS.
Pour les certificats, cert-manager s’occupe de la partie ACME avec Let’s Encrypt. Le challenge DNS-01 passe par Cloudflare. C’est pratique parce que je n’ai pas besoin d’exposer temporairement un endpoint HTTP juste pour prouver que je contrôle le domaine.
La documentation cert-manager recommande d’ailleurs les API Tokens Cloudflare, plus restrictifs et plus facilement révocables que les API keys globales cert-manager Cloudflare DNS01. C’est typiquement le genre de détail où un homelab devient un bon terrain d’apprentissage sécurité: on peut faire marcher le système, puis revenir dessus pour durcir proprement.
Prometheus et Grafana: voir avant de deviner
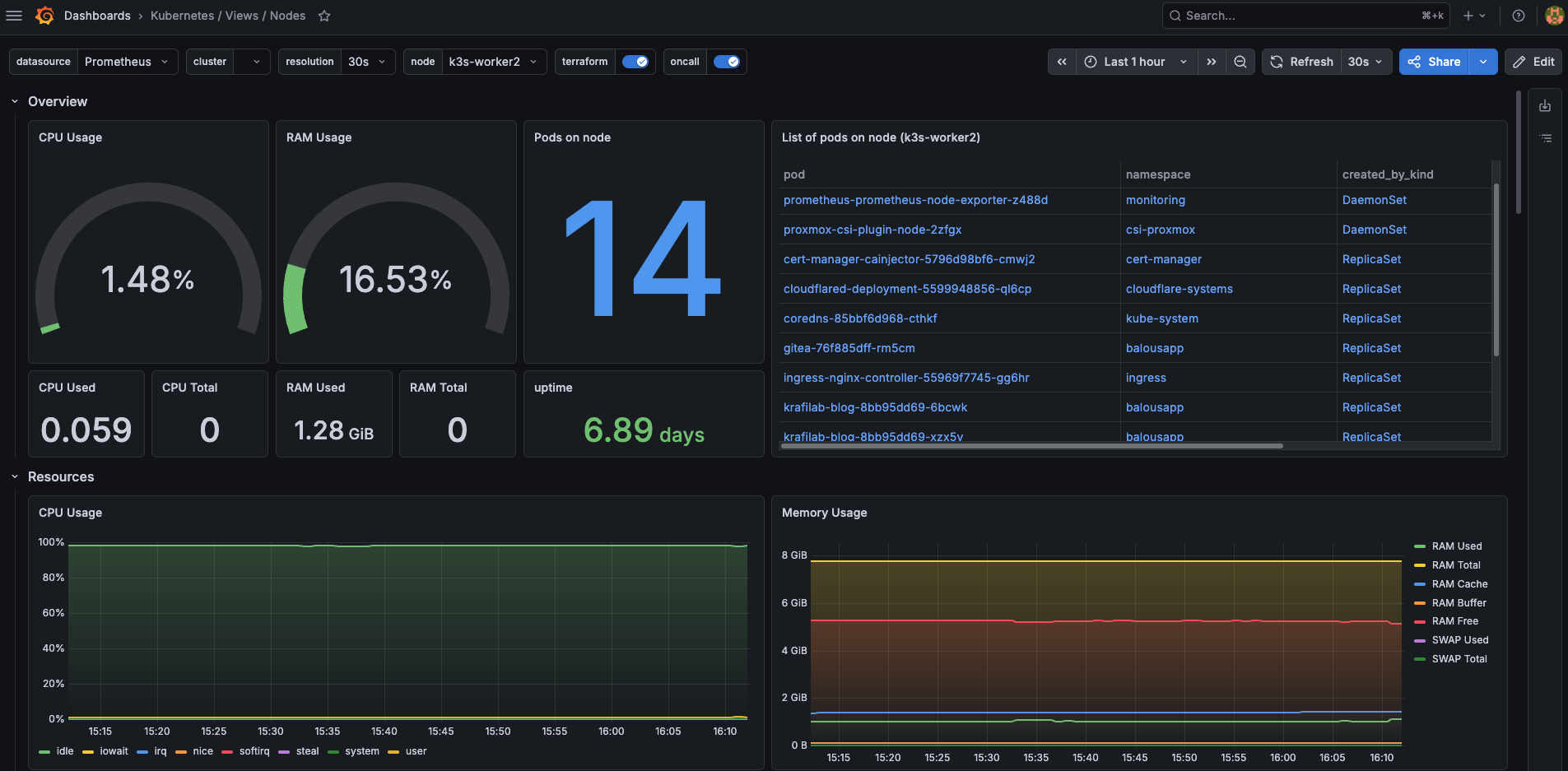 Un homelab sans observabilité, c'est un peu comme conduire de nuit sans phares. On peut avancer, mais on finit par comprendre les problèmes uniquement quand on tape quelque chose.
Un homelab sans observabilité, c'est un peu comme conduire de nuit sans phares. On peut avancer, mais on finit par comprendre les problèmes uniquement quand on tape quelque chose.
Prometheus collecte les métriques. Grafana les rend lisibles. Ce duo est classique, mais il est redoutablement efficace pour apprendre.
Prometheus fonctionne sur un modèle de collecte de séries temporelles, avec des labels et un langage de requête dédié, PromQL Prometheus overview. Grafana, de son côté, permet de requêter, visualiser, alerter et explorer des métriques, logs ou traces selon les sources configurées Grafana introduction.
Dans mon cas, l’objectif n’est pas encore d’avoir un NOC miniature avec trente écrans. Je veux surtout répondre à des questions simples:
- Est-ce que mon ingress reçoit du trafic ?
- Est-ce que Gitea répond correctement ?
- Est-ce qu’un pod redémarre trop souvent ?
- Est-ce que PostgreSQL devient un point de contention ?
- Est-ce que je vois les symptômes avant que le service tombe ?
Le simple fait d’ajouter des annotations de scrape Prometheus sur certains services change déjà la manière de raisonner. On ne se contente plus de “ça marche” ou “ça ne marche pas”. On commence à regarder comment ça marche.
Cloudflare Tunnel: exposer sans ouvrir grand la porte
L’exposition d’un homelab est un sujet sensible.
On veut accéder à ses services depuis l’extérieur, mais on ne veut pas non plus transformer sa box Internet en paillasson numérique. Cloudflare Tunnel apporte une réponse pratique: au lieu d’ouvrir des ports entrants, un agent cloudflared établit des connexions sortantes vers le réseau Cloudflare.
La documentation Cloudflare explique ce modèle outbound-only: cloudflared initie la connexion depuis l’infrastructure vers Cloudflare, puis le trafic circule dans ce tunnel sans nécessiter d’IP publique routable côté origine
Dans mon cluster, cloudflared tourne comme un Deployment Kubernetes avec plusieurs réplicas, un token porté par un Secret, et une sonde de readiness. C’est une brique discrète, mais elle répond à une vraie problématique: exposer des services sans multiplier les ouvertures réseau directes.
Ce n’est pas magique pour autant. Il faut toujours réfléchir aux accès, à l’authentification, aux tokens, aux services réellement publiés. Mais pour un homelab, c’est un bon compromis entre simplicité d’accès et réduction de la surface exposée.
What’s else (c’est ma réplique) ?
On est plus sur des docker-compose qu’on oublie en fin de journé mais on commence à avoir des vraies problématiques et des sujets qu’on peut retrouver dans de vraies entreprises. La suite est assez logique:
D’abord, stabiliser la stratégie de backup. C’est probablement le chantier le plus important surtout autour de PostgreSQL et Gitea. Une infra reproductible, c’est bien. Des données restaurables, c’est encore mieux.
Ensuite, renforcer la gestion des secrets. Aujourd’hui, certains accès sensibles existent encore sous une forme trop artisanale à mon goût: tokens, mots de passe, variables d’environnement, fichiers ignorés ou valeurs injectées à la main. Ça fonctionne, mais ce n’est pas encore une vraie stratégie.
Puis, pousser Argo CD pour que le cluster soit réellement piloté depuis Git, et pas seulement documenté dans Git.
Enfin, continuer à documenter tout ça. Parce que le but n’est pas uniquement d’avoir une stack qui tourne dans mon salon. Le but est de transformer chaque brique en apprentissage durable.
Au final, Pisely n’est pas juste une machine qui tourne dans un coin du salon. C’est un projet qui me ressemble: un mélange de curiosité, de bricolage, d’erreurs, de petites victoires et d’envie de comprendre vraiment ce qui se cache derrière les outils que j’utilise tous les jours.