Homelab - PART 1
Un homelab pour bidouiller et monté en compétence
Introduction : L’étincelle Numberly
Il fut un temps où l’envie de monter un homelab me démangeait : un espace pour bidouiller, expérimenter et, avouons-le, tout casser pour mieux reconstruire. L’idée de documenter cette aventure sur ce blog n’est peut-être pas révolutionnaire, mais elle est essentielle pour ancrer les connaissances.
Tout a commencé chez Numberly, la première entreprise où j’ai exercé. J’en profite pour passer une dédicace appuyée à toute la “Team Data” — Julien, Gabriel, Walid, Cyril : vous êtes les bests. C’est dans cet environnement technologique de pointe qui m’a donnée l’avant goût du on-premise. Chez Numberly, l’infrastructure est souveraine : du traitement de données aux couches applicatives, tout tourne sur les serveurs de l’entreprise. Cette immersion m’a donné le goût de la gestion matérielle et de l’optimisation bas niveau. Donc si vous êtes curieux et intéressé par une entreprise avec des enjeux tech jeter un coup d’oeil à ce qu’ils font.
Ce blog peut paraître “overkill” pour un simple site statique, mais le déploiement est un prétexte à la montée en compétence. De la sélection du matériel au choix des solutions logicielles, voici les coulisses de mon infrastructure personnelle.
L’Objectif : Résoudre une problématique… inexistante ?
Avant de sortir les tournevis, il fallait définir un objectif ou comme on dit dans le jargon corporate, identifier la “problématique métier”. En réalité, le but est l’expérimentation pure. Je voulais monter en compétence sur la gestion d’infrastructure et l’orchestration avec Kubernetes, afin de créer un socle solide pour mes futurs projets en Data et Software Engineering.
Vint ensuite le dilemme du matériel. N’ayant pas le budget d’une multinationale pour louer des serveurs dédiés ou consommer du Cloud à outrance, j’ai opté pour l’auto-hébergement. J’ai d’abord envisagé des Raspberry Pi pour leur compacité, mais les limitations en termes d’(I/O) et de performance CPU m’ont poussé vers des solutions plus robustes : les mini-PC de type HP EliteDesk ou Lenovo Tiny.
En écumant Leboncoin, j’ai déniché la perle rare : un HP EliteDesk équipé de 32 Go de RAM et d’un SSD NVMe de 256 Go. J’y ai ajouté un SSD d’un To pour le stockage. Pour une centaine d’euros, complétée par un mini-rack et un switch, Tadaaa Pisely est né.

Le nom “Pisely” trouve son origine chez Numberly
La Couche Software : Virtualisation et Automatisation
Une fois le matériel en place, la question de l’OS et de l’écosystème applicatif s’est posée. Le choix d’un hyperviseur s’imposait pour isoler les ressources et garantir une flexibilité maximale.
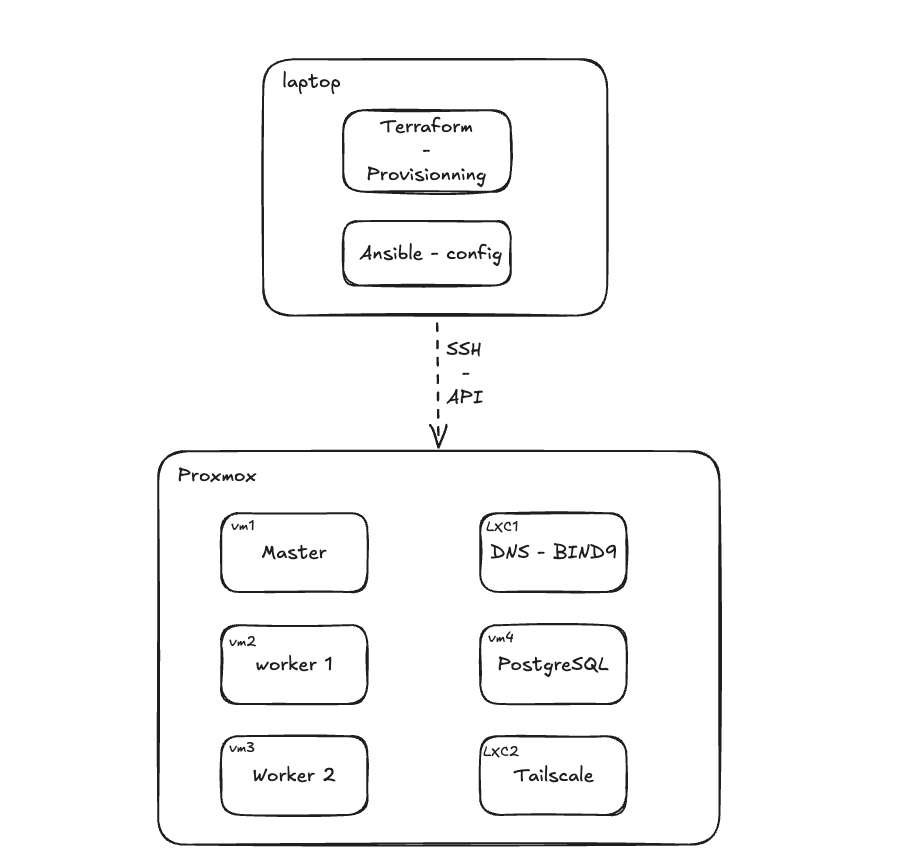
J’ai choisi Proxmox, une solution Open Source de référence. En tant qu’hyperviseur de type 1 (bare metal), il me permet de provisionner des conteneurs (LXC) et des machines virtuelles (VM) à la volée. L’un de ses atouts majeurs reste son API, qui permet de basculer vers une approche Infrastructure as Code (IaC) via Terraform.
Actuellement, l’architecture réseau reste simplifiée : pas encore de VLANs ni de segmentation complexe, faute de routeur dédié ou de switch manageable. Le homelabbing est un puits sans fond, et j’ai préféré prioriser les couches applicatives avant d’attaquer le réseau pur. À ce propos, si vous avez des recommandations pour un routeur performant ou un firewall (type OPNsense), je suis preneur !
Les services en production :
À l’heure actuelle, le cluster héberge :
-
K3s : Une distribution légère de Kubernetes (cluster de 3 nœuds : 1 Master, 2 Workers).
-
PostgreSQL : Instance de base de données relationnelle.
-
Bind9 : Un serveur DNS local pour la résolution de noms de domaine interne.
-
Tailscale : Un nœud de sortie VPN pour accéder à mon réseau de manière sécurisée depuis l’extérieur.
Le provisionnement n’a pas été intuitif immédiatement. La tentation de configurer via le shell est forte, mais l’adoption de Cloud-init a changé la donne. Grâce à la création de templates de VM, je peux désormais automatiser la définition des utilisateurs, l’injection des clés SSH et l’installation des packages de base dès le premier boot.
What’s next ?
Ce premier article pose les fondations de Pisely. La suite sera dédiée à des sujets plus pointus, mais pas que. Ceci dit j’aimerai bien aboardé des sujets:
-
Data Engineering : Pipelines ETL, moteurs d’exécution, stratégies de stockage et modélisation, Optimisation.
-
Software Engineering : Algorithmique, Design Patterns et méthodologies de test.
-
Infras/Ops : Kubernetes, Monitoring, Systèmes …
-
Pense bêtes : Ce qui trame dans ma tête hors sujets techs
La curiosité est mon moteur, et mon objectif est de transformer ces explorations en cas d’usage concrets. L’aventure ne fait que commencer.